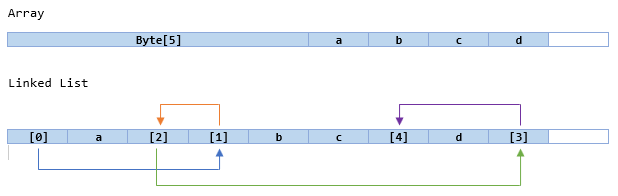
In the past, I have used Windows Preview Handlers as a convenient means of previewing documents inside my Windows Forms applications. The main advantage of this was not having to write my own previewing logic for a (potentially limitless) range of file formats, and using a standard OS feature that has been widely supported since Windows Vista.
Unfortunately, one of the great benefits of preview handlers has also caused a lot of headaches for me; not all implementations are created equally. Some handlers are well-written and play nice with .NET hosts, others have major bugs and memory leaks, and some simply do not work at all. And one of the worst culprits is Adobe’s PDF Preview Handler, installed along with Adobe Reader and Acrobat.
I’ve now come to the conclusion that, at least for PDFs, Preview Handlers are no longer a viable solution and a more reliable alternative is needed. The problem is that generating a preview for a PDF document is no trivial exercise – to do so requires a parser, a PostScript interpreter, libraries for typography, image processing, compression, cryptography and more. While I have been experimenting with all of these, I needed something that was suitable for immediate production use.
Enter, PDF.js…
PDF.js is a JavaScript library, developed by Mozilla Labs, that can be used to view PDFs in a web browser. It is the basis for the built-in PDF viewer in Firefox, but also works in other browsers. Unlike other mechanisms, it requires no operating system or third party PDF applications to be installed, being completely self-contained. It’s also small (around 4MB) and performs quite well.
If I was developing a web application, I would most certainly leverage PDF.js to preview documents – it’s the obvious choice, really. However, working mostly in the desktop world, I needed a way of utilising this excellent library in the Windows Forms environment.
The WebBrowser problem
The built-in WebBrowser control is a handy way of leveraging HTML/JavaScript content inside a desktop application. As well as being able to display content alongside other controls on a form, there is also some limited interactivity possible between the DOM and the hosting application. So on face value it might seem like a good way to leverage PDF.js…
Problems:
- For compatibility reasons, the browser runs in Internet Explorer 7 emulation mode, which lacks proper, standards-compliant HTML, CSS and JavaScript support.
- The PDF.js viewer does not work properly unless loaded over HTTP – a file URL is not sufficient.
- PDF.js (in the majority of cases) can only render documents loaded from the same origin (domain) as itself.
Solving these problems with a local HTTP server
The first problem has been largely solved by PDF.js already; it is possible to override the compatibility settings for the web browser control by including the X-UA-Compatible meta tag in the <head> section of the HTML page. This elevates the browser to Internet Explorer 11 mode. A version of PDF.js built for ECMAScript version 5 browsers (including IE11) is available, making it possible to use the viewer in that browser.
The other two problems require a more drastic solution; since the script expects to be loaded over HTTP, we need to serve it using a local HTTP server. Ideally this should be something lightweight that does not require additional setup or elevated privileges to run. Due to the same-origin requirement, we also need a way of ensuring that the document loaded into the viewer can be accessed via the same server.
To meet these requirements, I chose NHttp – a simple embedded HTTP server with no other dependencies. Unlike the .NET Framework’s built-in HTTP server based on http.sys in Windows, NHttp does not require URL reservations and therefore does not require admin privileges to run. It also spins up quickly, making it very desirable for our needs.
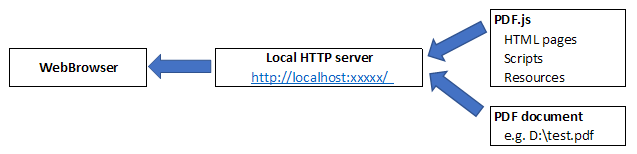
The server simply acts as a proxy between the PDF.js scripts, the document to be previewed and the web browser. It places them behind an HTTP URL and ensures that they are accessed from the same origin (even if their true locations differ). Together, this solves all of the problems above.
How it works
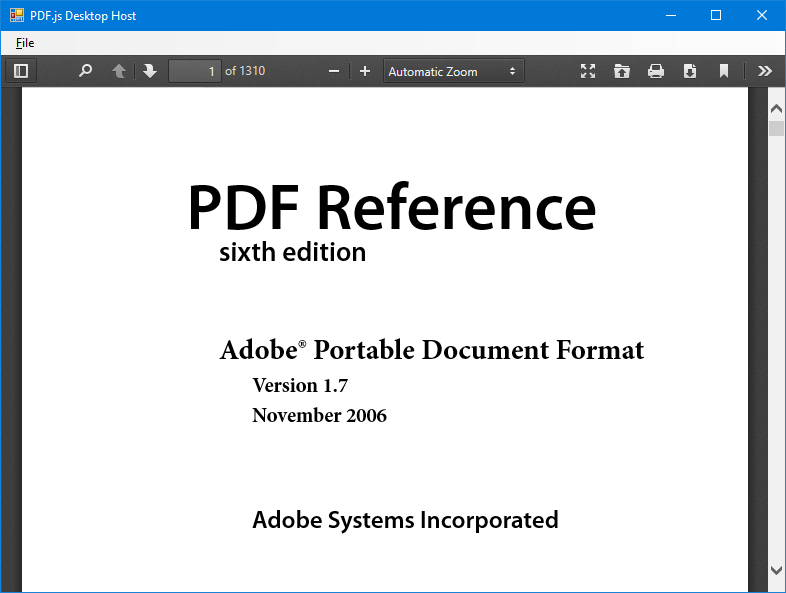
From start to finish, the process of previewing a PDF inside a WebBrowser control is as follows:
- The PDF.js files are extracted to a temporary directory when the component is initialised. By storing these inside the assembly as an embedded resource, the project has an even lighter footprint.
- The HTTP server starts listening on the local IP address, using a random port number so as not to interfere with any other services that might need port 80.
- The application registers a local filename (which could be on another drive or network share) with the server, in exchange for a unique URL that will be used to display the preview. (In theory, this could also be an in-memory stream or even a document located at another URL) This URL points to the PDF.js viewer, preloaded with the correct document.
- The application navigates the
WebBrowsercontrol to the URL obtained in the previous step. - The server receives multiple requests. Depending on the path:
- If the path starts with “/doc”, then the local filename registered in step 3 is served to the browser.
- If the path corresponds to one of the PDF.js source files, that file is served to the browser.
- The
WebBrowserloads the viewer, and PDF.js loads and displays the document to the user. - When the application no longer needs to display the preview, the HTTP server can be stopped. At this point, the temporary directory can be cleaned up as well.
Example:
// register the local file with the HTTP server string url = host.GetUrlForDocument(openFileDialog.FileName); // open in embedded web browser webBrowser.Navigate(url);
Implementation notes
The Host class (which implements the HTTP server and the registration method) implements the IDisposable pattern. It is important that caller properly disposes the component or else the application may not exit.
For performance and responsiveness reasons, the PDF.js files are extracted asynchronously after the host is initialised. This assumes that some time will elapse before the first document preview is loaded (otherwise, the main thread will block until the process has completed).
The HTTP server supports GET, HEAD and OPTIONS methods (even though the browser seems not to take advantage of the latter two). It also supports the If-Modified-Since request header and allows the browser to cache the content. This could improve loading times for subsequent previews.
Once a local filename is registered with the host, its URL remains valid for 30 minutes after it was last accessed.
Source code
The project is available on GitHub, along with a demo application: https://github.com/BradSmith1985/PdfJsDesktopHost